
With over a decade in software development, I’ve repeatedly faced the challenge of scaling underperforming services. Python is an excellent language for rapid prototyping, offering a wealth of libraries and frameworks. However, as a project grows, its performance can become a bottleneck, and latency issues can quickly threaten stability and degrade the user experience.
In this guide, I’ll share practical, battle-tested solutions to help you optimize your Django service and significantly reduce request response times.
The Challenge: A Trial by Fire
My first day at a new company began with the CEO’s urgent message: “We had a major outage yesterday. We need to fix it and ensure it never happens again.”
The root cause was clear: during normal operation, the load was manageable, but during peak traffic from major public events, tens of thousands of users would connect simultaneously. Despite existing caching and scaling efforts, our Django application couldn’t handle the surge. This article details the steps we took to overcome this challenge and emerge from a high-traffic period like the New Year’s holidays with minimal disruption.
Identifying the Bottleneck
If you’ve researched Django optimization, you’ve likely encountered standard advice: fix N+1 queries, add database indexes, implement caching. These are all excellent recommendations. In our case, however, this foundational work was already done — and it wasn’t enough.
The symptoms during peak hours were:
- Users mass-launched the app or website.
- After a brief authentication, they requested a video stream.
- To find the stream, the app had to load the program schedule.
- To load the schedule, it needed user data, subscription status, content availability checks, and numerous other permissions.
This required querying multiple database tables, creating a complex and slow chain of events. Our top ten most frequent requests during peak load were all related to:
- User profile data
- Electronic Program Guide (EPG) data
- Channel/show metadata
- The actual video stream request
By analyzing the frequency, timing, and data volume of these requests, we knew where to start.
Our Optimization Strategy
Our service streams video to users across different regions and countries. Content is often subject to complex licensing restrictions (geoblocking) and user-specific rules based on subscriptions and even their Internet Service Provider (ISP). This meant generating a final server response required fetching vast amounts of dynamic, user-specific data from the database, making it impossible to cache a single response for all users.
We focused on two primary optimization paths:
- Smart Caching: Cache data that doesn’t change frequently within a user session.
- Faster Serialization: Utilize modern, high-performance JSON libraries that leverage CPU advancements like SIMD.
1. Smart, Targeted Caching
Analysis revealed that several sequential API calls required the same user profile data: subscriptions, ISP binding, region, etc. This data is largely static for the duration of a session. While a subscription could expire or a user could change networks, we could safely check this data at discrete intervals (e.g., every 5 minutes).
The challenge was deciding how to store this data in the cache. After testing several options, we settled on using Redis Hashes, which demonstrated the least overhead. The structure looked like this: text
{
"profile:12345": {
"region": "EU-WEST",
"isp": "some-isp-id",
"subscriptions": ["premium", "sports"],
...
}
}Pro Tip: Before implementing a cache, always calculate the required data volume and configure an appropriate Eviction Policy. Based on our usage pattern, we chose allkeys-lru.
2. High-Performance Serialization with orjson
While Python has many JSON libraries (ujson, rapidjson, orjson), not all are created equal. Since the early 2010s, processors have featured SIMD (Single Instruction, Multiple Data), which allows parallel execution of an operation on multiple data points using vector registers. By the 2020s, advanced extensions like AVX-512 became available, and some libraries harness this power for parsing and serialization.
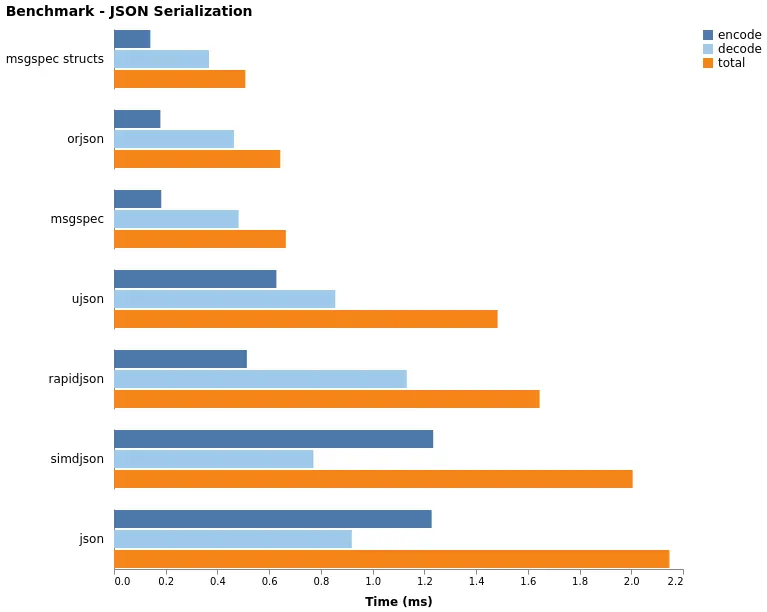
Many developers default to ujson, a common and well-documented choice. Unfortunately, it was no longer sufficient. Our search led us to two libraries that significantly outperformed the standard json and ujson: orjson and msgspec.
We chose orjson for two key reasons:
- Memory Safety: It’s written in Rust.
- Minimal Code Changes: Integration was incredibly simple.
We only needed to change a few lines in settings.py:
REST_FRAMEWORK = {
"DEFAULT_RENDERER_CLASSES": (
"drf_orjson_renderer.renderers.ORJSONRenderer",
"rest_framework.renderers.BrowsableAPIRenderer",
),
}The payoff was massive. Beyond speeding up API responses, JSON serialization is heavily used in inter-service communication. By switching the serializer, we accelerated multiple parts of our system at once. For large datasets like the program guide, this shaved off hundreds of milliseconds.
Performance Benchmark (Lower is Better):
| Library | Time (sec) | Speedup vs. json |
|---|---|---|
| json | 0.00479 | 1x (Baseline) |
| orjson | 0.001179 | 4.06x faster |
| msgspec | 0.000629 | 7.62x faster |
| ujson | 0.003957 | 1.21x faster |
| simdjson | 0.004636 | 1.03x faster |
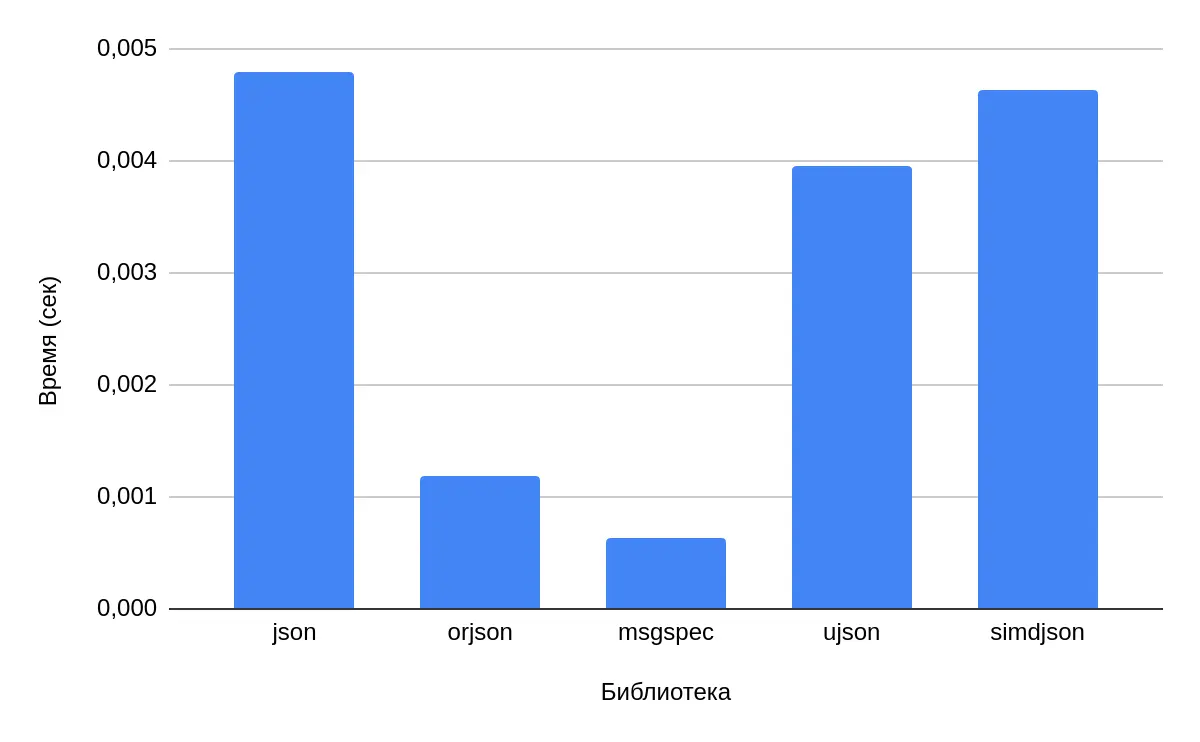
Pro Tip: Always test different options for your specific data and use case to find the best fit.
Additional Performance Tweaks
The work didn’t stop with caching and serialization. We made several other key improvements:
-
Data Reduction: We analyzed payloads and database queries, eliminating unused data. This reduced the response size of some endpoints (user profile, content metadata) by up to 20%.
-
Asynchronous Handlers: Starting with Django 4.0, we adopted async views. While this doesn’t speed up a single request, it dramatically improves concurrency and overall throughput for I/O-bound tasks by using resources more efficiently.
-
Garbage Collection Tuning: We noticed Python’s GC was triggering too frequently due to the allocation of millions of objects from processing large data structures. The default thresholds were too low for our workload. We adjusted them for better performance:
import gc # New thresholds: 10_000 allocations, 100 gen1 collections, 100 gen2 collections gc.set_threshold(10000, 100, 100)This yielded a ~5% improvement in response times without impacting memory stability.
Warning: GC tuning requires careful testing. Always validate stability before deploying to production.
-
Python Version Upgrade: We upgraded from Python 3.8 to 3.11. This required updating some code and dependencies but provided a ~10% performance boost out of the box, thanks to ongoing optimizations in the interpreter itself.
Results and Key Takeaways
The combined effect of these optimizations was cumulative and decisive. We achieved our goal of stability during peak loads.
-
Drastically Reduced Latency: The 99th percentile response time for key endpoints (program guide, video stream) dropped from 900-1500ms to a stable 250-600ms.
-
Database Load Relief: Database queries during peak times were reduced several-fold thanks to smart caching and data reduction. Final server CPU load stayed below 50%, compared to 90%+ before the changes.
-
Increased Throughput: Our application servers handled up to 3x more requests per second on the same hardware due to reduced CPU load (from
orjson) and more efficient resource usage (async, GC tuning).
The final takeaway: There is no silver bullet for performance. High performance is the result of a systematic approach and attention to detail. Standard optimization advice provides a necessary foundation, but weathering real-world traffic storms requires deep analysis and a willingness to implement precise, sometimes non-trivial, changes.
Start with profiling, find your specific bottlenecks, and be prepared to dig deeper than common practices. If your Django service is struggling, don’t be afraid to go beyond the docs. Use metrics, Django Debug Toolbar, and flamegraphs. Try orjson and experiment with GC settings — sometimes, it’s these finer details that save you under millions of requests.